Contents
- Definition of Linked List
- Implementation
- Performance
- Sample Application
Definition of Linked List
- Consists of Nodes
- Node : unit of storage (item)
- Nodes are linked with pointers ( what does that mean? )
**Pointer: Simply Stores an Address
Linked list는 배열과 다르게 메모리 아무데나 있을 수 있다. 대산 한 노드에 가면(=한 노드의 주소를 알아서 그곳의 내용을 읽으면) 다음에 갈 노드의 주소가 적혀있다. 즉 노드들이 포인터들도 연결이 되어 있는 것이다.
Linked List의 노드의 구조를 살펴보면 다음과 같다.
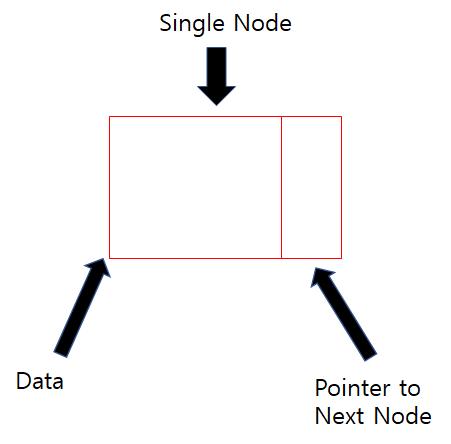
Whole List
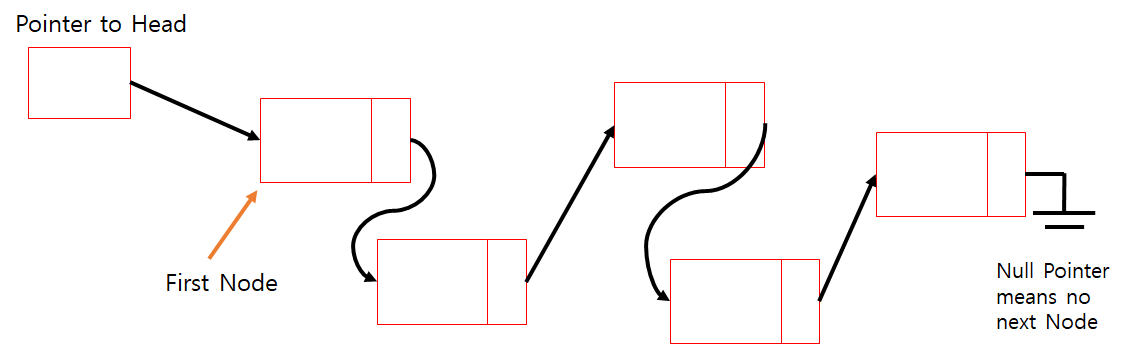
이런식으로 구성이 되어있다. (화살표 등은 사람이 보기 쉽게 표현한것이다.) 마지막 노드에는 더이상 갈 곳이 없으므로 null값을 넣는다. 첫번째 노드로 갈때는 어쩔수 없이 그 노드를 가리키는 포인터를 가지고 있어야 한다.
Code for List
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
class Node {
int a; // data
Node *n; // 다음노드에 대한 주소
};
class List {
List::List();
List::~List();
int Search(...);
int Insert(...);
int Delete(...);
Node *head;
};
...
// examples
List A;
A.head= NULL;
A.Search(8);
|
Construction, Destruction
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
List::List()
{
head = NULL;
}
List::~List()
{
Node *p, *q;
p = head; //p가 같은 곳을 가리키게 됨.
while( p != NULL){
q = p -> n
delete p; // p가 가리키고 있는 곳이 delete
p = q;
}
}
|
Search
-
Assume Sorted Order (Other Ordering of course possible)
Search Code
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
int List::Search(int x, Node **p, Node **l) //x는 찾을 값 ㅣ이 현재 보고 있는 node
//p가 직전에 본 node
{
*p = NULL;
*l = head;
while(*l != NULL){
if((*l)-> a > x) return 0; // 실패
else if ((*l)-> a == x) return 1;
else{
*p = *l; // 같은 곳을 가리키기
*l = (*l) -> n;
}
}
return 0;
}
Node *P, *L;
res = A.search(8, &P, &L); // res == 0 이면 실패 res == 1 이면 성공
|
Insert 그림
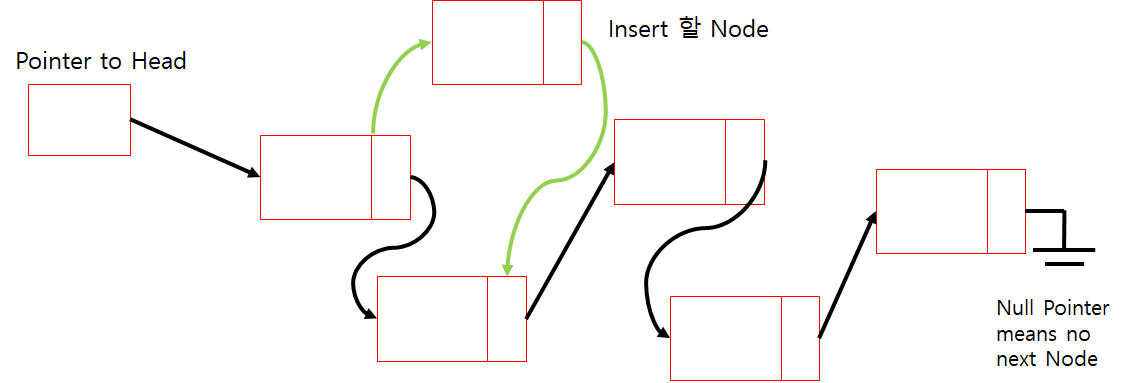
Insert Code
|
1
2
3
4
5
6
7
8
9
10
11
12
|
int List::Insert( int x )
{
Node *P, *L, *N;
res = search(x, &P, &L);
if(res == 0 ){
N = new Node; // 새로운 노드 할당
N -> a = x;
if(P == NULL) head = N; else P -> n = N;
N -> n = L;
}
else return -1;
}
|
Delete 그림
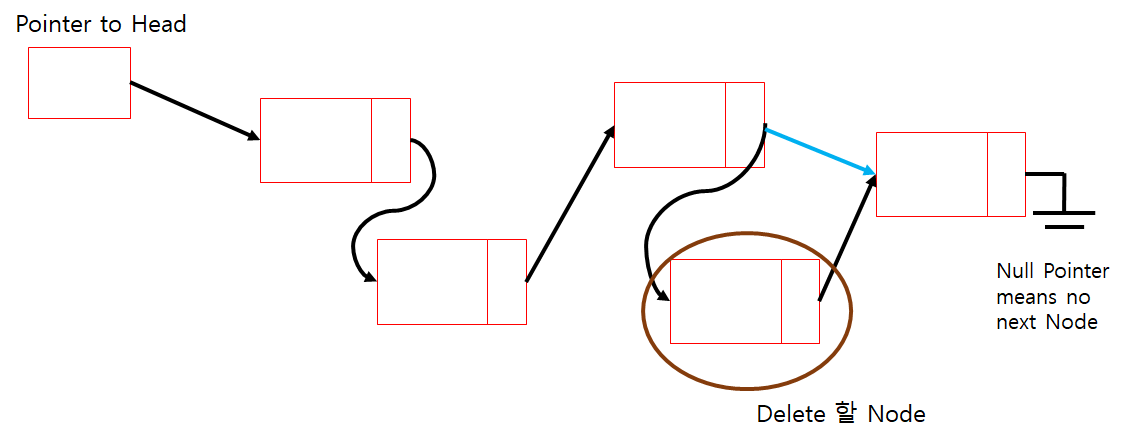
Delete Code
|
1
2
3
4
5
6
7
8
9
10
11
|
int Delete( int x , Node **d)
{
Node *P, *L;
res = search(x, &P, &L);
if (res == 1) {
*d = L;
if(P == NULL) head = L->n; else P->n = L->n;
}
else return -1;
}
|
Performance( 성능 평가 )
- Sorted(정렬)
- Search: O(n) , Insert: S + O(1) , Delete: S + O(1)
- UnSorted(정렬 X)
- Search: O(n) , Insert: S + O(1) or O(1) , Delete: S + O(1)
- LRU (Least Recently Used, Paper on Desktop), 사용한 노드를 head로 이동
- =>자주 사용하는 값을 앞으로 놓자
- 최악- Search: O(n), Insert: O(1) , Delete: S + O(1)
- 기대- 사용 빈도에 따라 크게 다름.
Comparison with std:: vector( Standard vector 와 비교 )
- Vector: Variable-Size Array(사이즈가 늘어나고 줄어들 수 있는 배열)
- Sorted
- Search: O(log n), Insert: S+ O(n) , Delete: S+ O(n)
- Unsorted
- Search: O(n), Insert: S + O(1), Delete: S + O(1)
Variations: Dummy Nodes
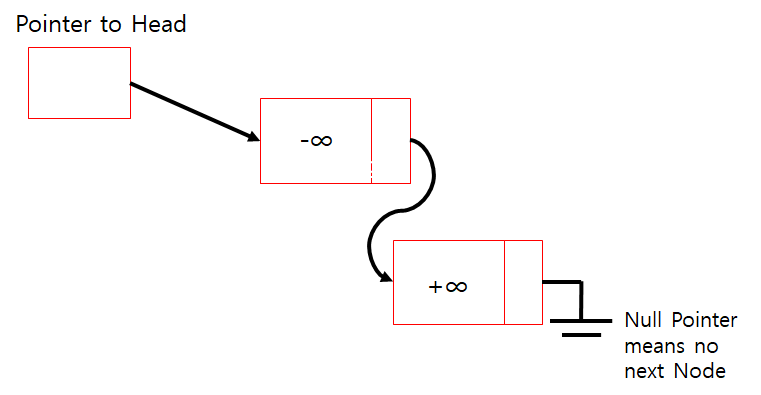
Standarad Linked List에 대부분 포함되는 구조. 처음에 만들때 노드를 두개 만들고 하나는 마이너스 무한대 하나는 플러스 무한대 값을 집어넣는다. 이 두 값은 실제로 사용하는 값은 아니고, 미리 경계를 정해놓는 것이다. 이렇게 해놓으면 못찾았을때 (실패했을 때), P와 L이 NULL인 경우가 없어지게 된다.
Variations: Circular List
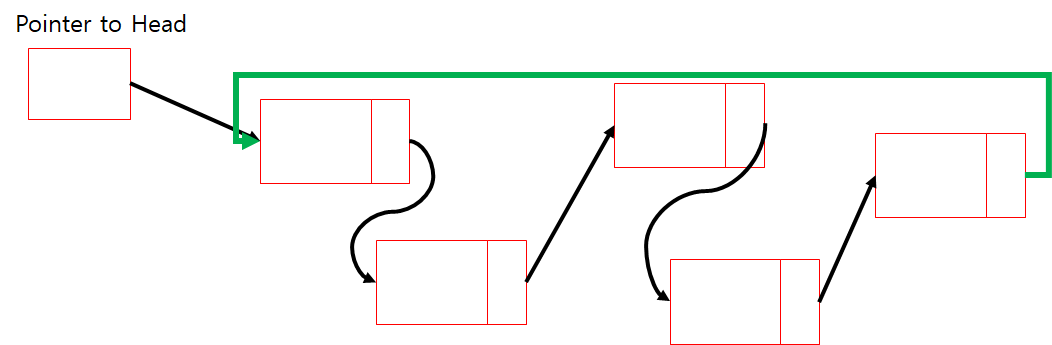
Circular Queue 등을 만들때 쓰임, 성능이 달라지는 일은 없다. 특이한 상황에서 쓰이는 구조.
Variations: Doubly Linked List
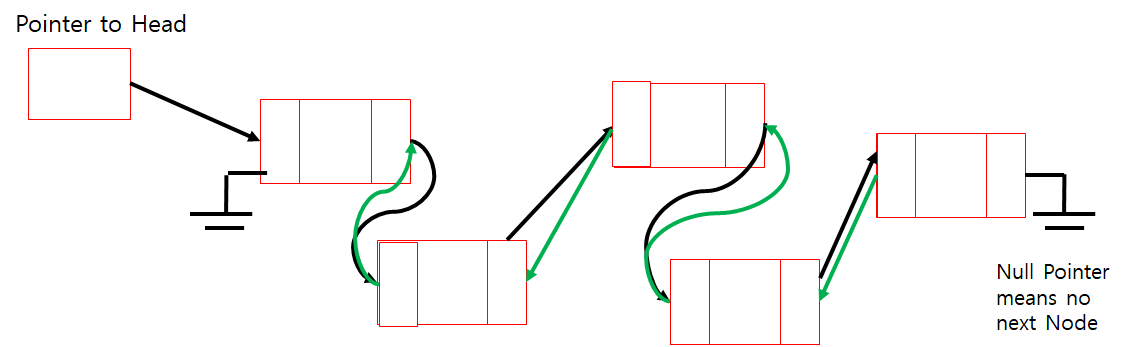
성능이 달라질수 있음. 양방향으로 연결되어있어서 노드 앞뒤로 갈 수 있는 구조. 성능이 크게 달라지는 일은 없다.
Another Application : Linked Stack
-
Push
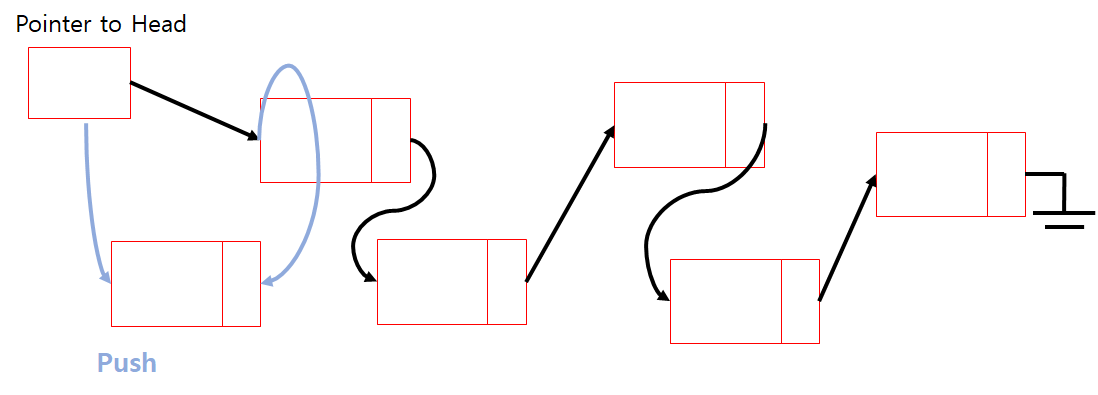
-
Pop
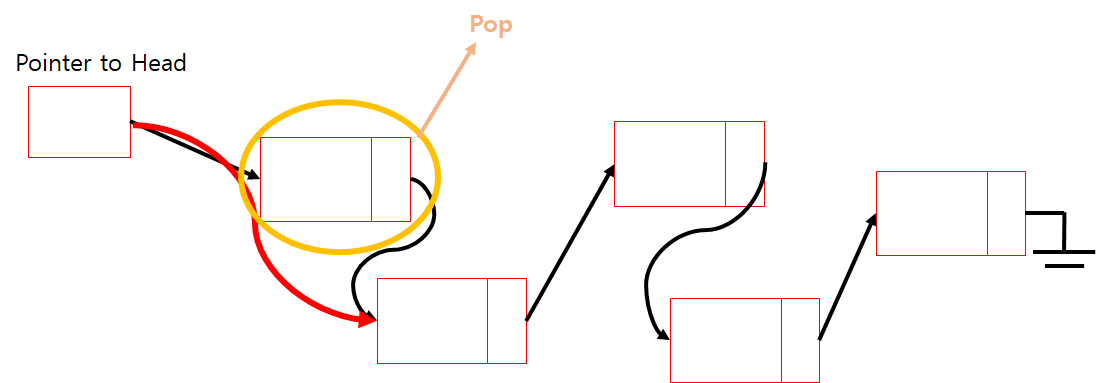
And Another: Linked Queue
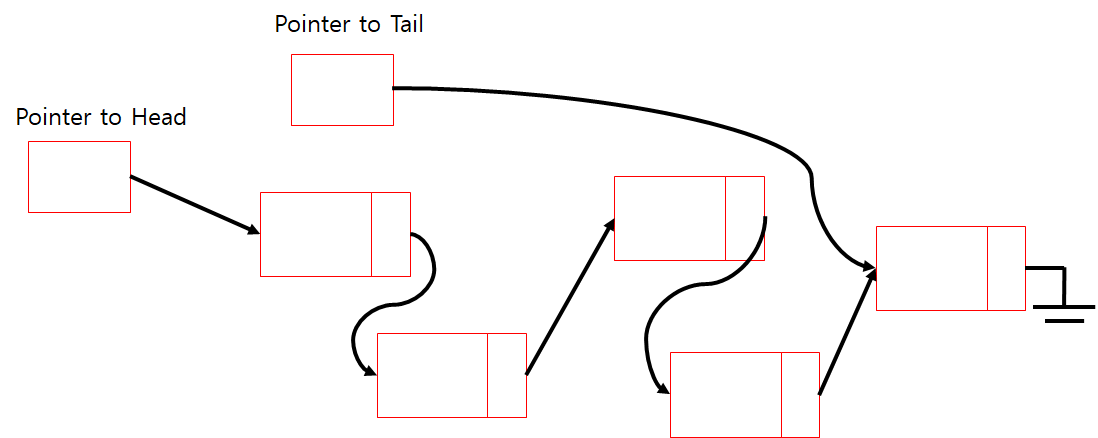
다만 이 구조에서는 Delete는 불가능 하게 된다. (대신 Doubly Linked List 일떄는 가능)
More
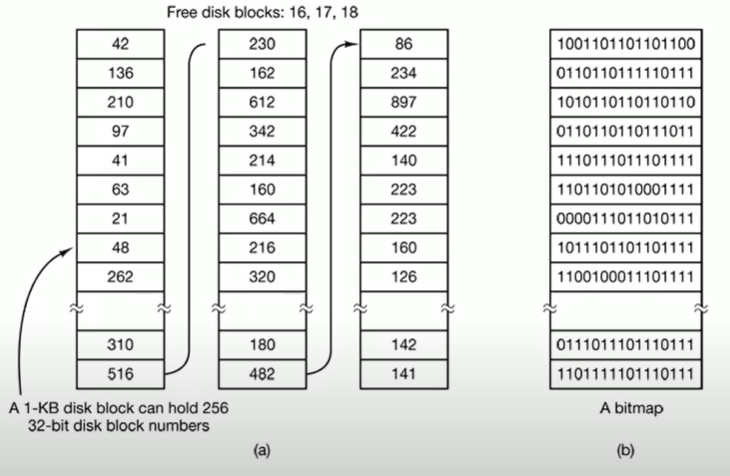
- Free Block List : in Array, Disk File System
- Polynomial Representation
- Array case, list case, eval, add, multiply
- Sparse Matrix
- Example Figure
- Sparse Matrix Implementation
- Sparse Matrix Multiplication
- Dynamic Memory Allocation
- The situation, How to find free space
- Skip List
Free Block List on File Systems
Polynomial Representation

- Array Version
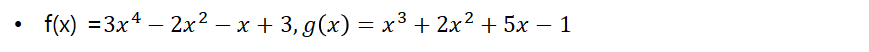
- f(x) + g(x) = ?
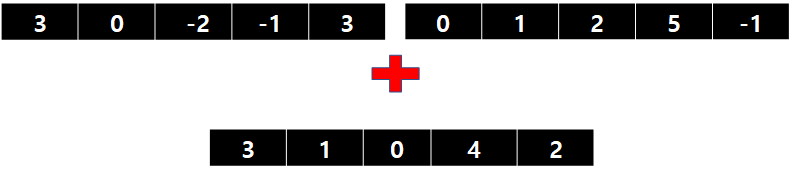
List Version
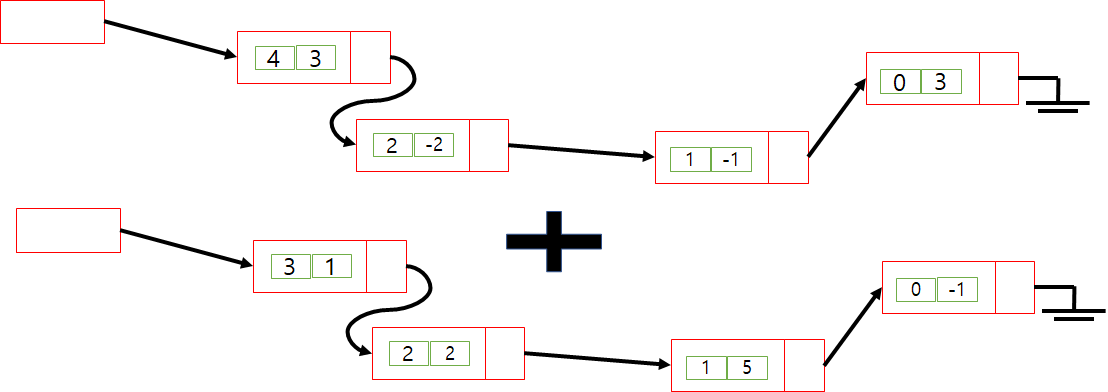
# 과정 :
각 링크드 리스트 노드의 왼쪽값을 비교한다. 두 노드의 첫번째 왼쪽값을 비교해보면 4와 3이다. 다를 경우 큰 값을 복사한다. 그리고 사용했으면 다음 노드와 비교한다. 노드가 같을 경우는 오른쪽값을 더한값을 답 노드 오른쪽에에 집어 넣는다.이런식으로 반복해서 결과 리스트를 만든다.
# Result :

Sparse Matrix (0의 비율의 많은 Matrix)
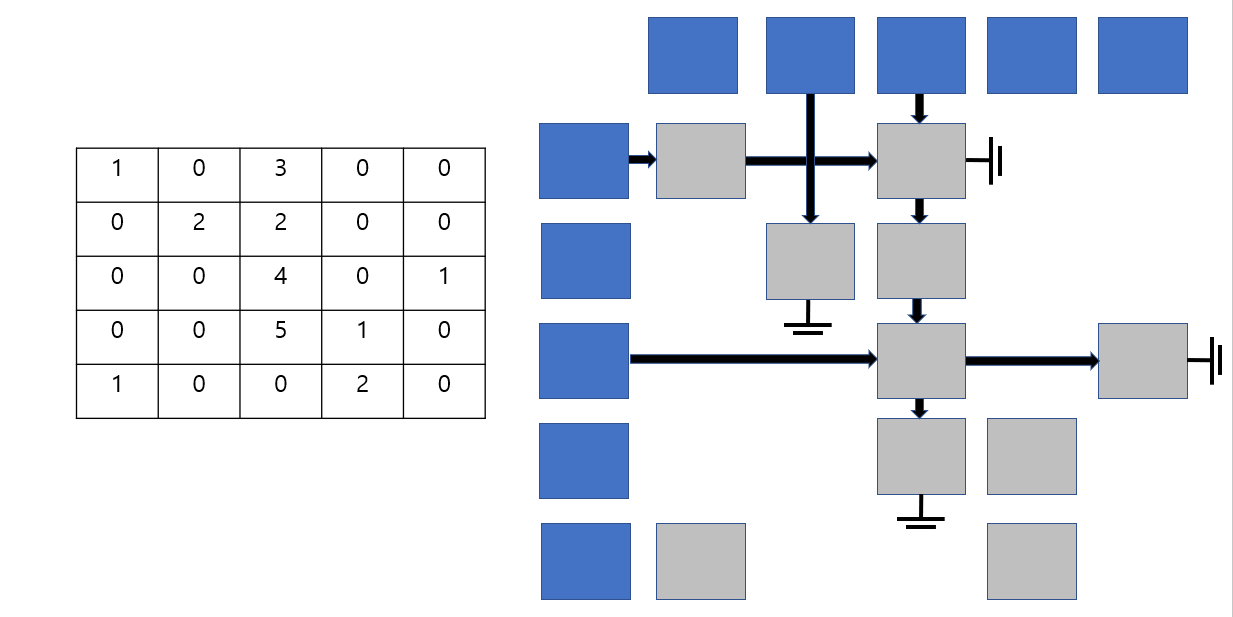
그림과는 다르게 보틍은 doubly linked list로 이를 나타내는것이 편하다.
Sparse Matrix Code
|
1
2
3
4
5
|
class Node {
int a, r, c;
Node *up, *down, *left, *right; // double linked 가정
}
|
Sparse Matrix Multiplication( 두 개의 행렬 곱하기 )
행렬의 곱은 부텉 한 행렬의 column 과 다른 행렬의 row의 자리들을 곱하는 형식인데 위의 링크드 리스트를 활용한
matrix에서 두 행렬의 곱셉의 결과를 출력 할 수 있다.
Memory Allocation
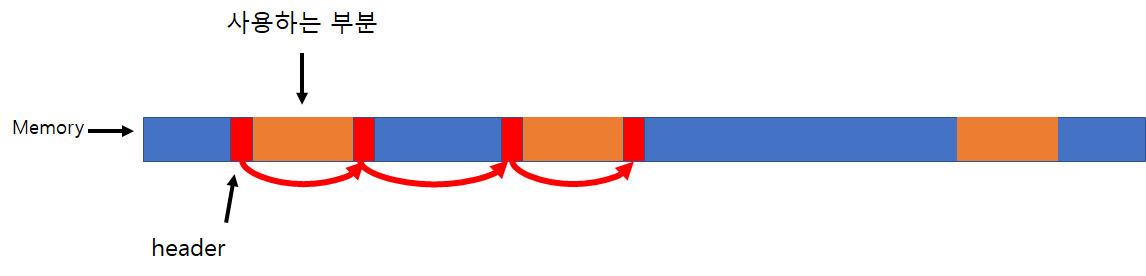
헤더들이 Linked List들로 연결되어 있어서 메모리를 할당 하라는 명령을 받았을때 링크를 따라가면서 적당한 사이즈가 있는지 확인하는 방법으로 활용(물론 매우 거시적으로 설명한뜻 성능 향상을 위해 좀더 복잡한 것들이 쓰임.)
Skip List
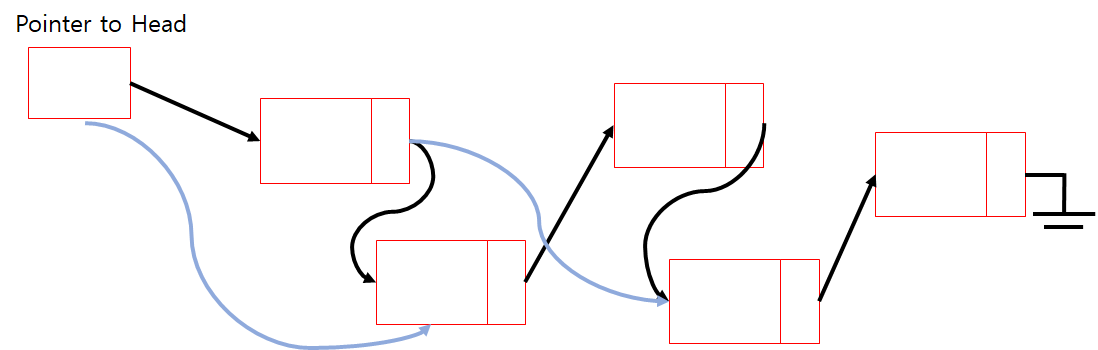
멀리 가는 포인터를 포함해 두면 Linked List로 Binary Search 비슷하게 활용할 수 있다. (멀리 가보고 값을 비교해 보기)
B+ Tree
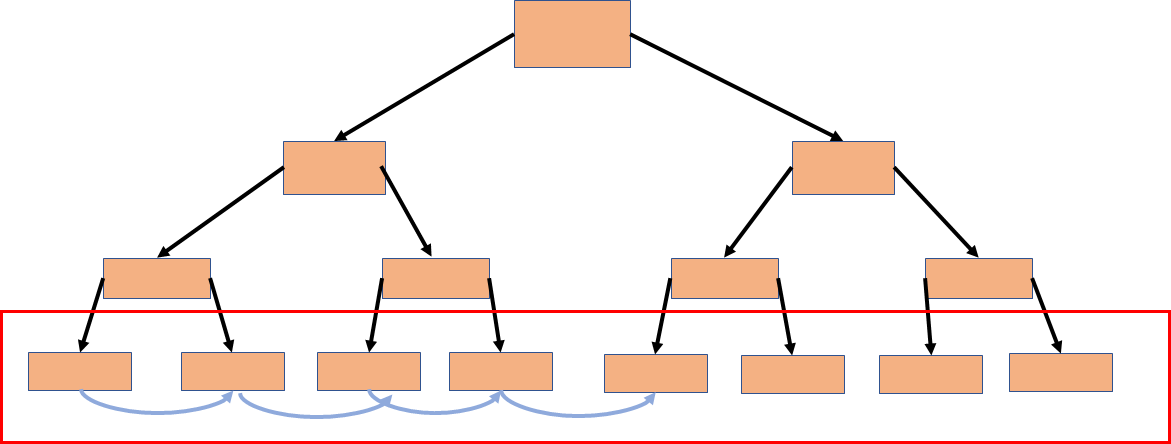
아직 본격적으로 배우지 않았지만 이런 tree 구조(각 노드의 왼쪽에는 노드보다 작은값 오른쪽에는 큰 값을 넣는 구조)에서 가로 방향으로 이동할 수 있게 끔 링크를 줘서 search 작업을 할때 보다 빠르게 수행할 수 있게끔 활용한다.
Fractal

이러한 fractal 이미지를 구현할때도 각 노드가 연결이 된 링크드 리스트를 활용해서 나타낸다. 기회가 되면 코드도 이러한 이미지를 구현하는 코드도 포스팅 해보겠다.
** 결론: Linked List는 search에서 좋지 않은 성능을 보여주기 때문에 많이 쓰일거 같지 않지만 위의 다양한 쓰임새를 보았듯이 특정한 상황에서 자주쓰이는 자료구조이다.
이것으로 기나긴 linked list 편을 마친다. 다음에는 다른 자료구조로 찾아오도록 하겠다.
'프로그래머, 보안 관련 지식 > 자료구조' 카테고리의 다른 글
| 자료구조 : Tree(2) - Binary Search Tree- (0) | 2020.05.05 |
|---|---|
| 자료구조: Tree(1) - Binary Search Tree - (0) | 2020.05.04 |
| 자료구조: Equivalence Relation(동치 관계) (1) | 2020.04.26 |
| 자료구조: Stack & Queue (3) (0) | 2020.04.25 |
| 자료구조 : Stack & Queue(2) (0) | 2020.04.25 |


