이번 포스팅에서는 String Matching이 뭔지에 대해 알아보자.
Problem Defintion
- Text : Simple String of Characters
- Pattern: Simple String of Characters
- To Do : find where in the Text Pattern Occurs
String Matching 문제는 Text 에서 패턴을 발생하는 곳을 찾는 문제이다.
abababcabcabcdabccbaabdabcabcdabcd
다음과 같은 text에서 abcabcd 를 찾는 문제라고 생각해보자. 일반적으로 사람이 이 일을 할때 어떻게 할수 있을까?
대보면서 한글자씩 옆으로 밀어가며 찾을 것이다.
이 방법은 상당히 느린 작업이고 이것보다 더 빠르게 찾는 방법이 존재한다.
어떤 알고리즘이 있는지 알아보자.
1) Naive 알고리즘
Naive 알고리즘은 아까 위에서 설명한 사람이 한 것과 같은 방식의 알고리즘이다.
사람이 할때는 패턴을 하나씩 옮겼지만 컴퓨터로 이를 구현할때 어떻게 표현해야 할까?
코드로 표현하면 다음과 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// n 은 문자열의 길이
// 인덱스는 1부터 시작
// m은 패턴의 길이, output은 출력하기 위한 배열
int naivematch ( char T[], int n, char P[], int m, int output[] )
{
int i, j, k;
for (i = 1; i<=n; i++) output[i] =0 ; // 전부 0으로 초기화
for( i=1 ; i <= n - m+1; i++ ){
for(j = i, k=1; k<=m; j++, k++)
if(T[j] != P[k]) break;
if (k == m+1 ) output[ j-1] = 1 ;
}
}
|
i가 텍스트 첫글자 , j는 텍스트를 읽을 인덱스, k는 패턴을 읽을 인덱스이다.
j와 k 값을 비교해서 하나라도 다르면 루트를 빠져나가고 같은경우 매치가 끝나는 지점에 1로 표시한다.
시간은 얼마나 걸리게 될까? 대략적으로 텍스트길이 n 과 패턴길이 m을 곱한 O(nm) 이 될것이다.
공간은 어찌되었든 텍스트 길이 n에서 움직이므로 O(n) 정도 나올것이다.

2) DFA 알고리즘
DFA 알고리즘은 위의 문제에서 정해진 약속대로 숫자를 적어 패턴을 찾아내는 알고리즘이다.

abcabcd 패턴을 이런식으로 숫자를 활용해 패턴을 찾아 내는 것이다. 이 숫자는 무슨 의미일까? 자세히 설명을 하겠다.
컴퓨터에서는 이런방식을 활용하기 위해 다음과 같은 테이블을 활용하게 된다.
이러한 방식의 테이블을 사용한다. (맨 위 알파벳은 제외, 설명을 위해 만듦) abcd는 텍스에 있는 문자이고
숫자가 0~7까지 있는것은 우리가 찾아야 할 패턴이 7글자이기 때문이다.
숫자가 0 이면 a일때 1을 적는다 라는 뜻이고,
숫자가 1 이면 b일때 2을 적는다 라는 뜻이다.
위의 숫자는 그전 알파벳을 나타내는 숫자이고, 옆 알파벳은 그전 알바벳이 나왔을때 현재 알파벳이 나올때를 나타낸것이며 안에 들어가는 값은 현재 알파벳에 적어야할 숫자이다.
4번째 b 글자부터 시작했다고 가정해보자. 일단 시작점에 2가 있다. 그다음으로 a가 나오면 어케 될것인가?
2라는 뜻은 일단 그전에 ab까지 나왔다는 뜻이고 그다음으로 c가 나오면 3을 적는다. 그렇지만 a가 나오면 어떻게 될까?
다시 처음으로 돌아가서 패턴을 확인할 필요가 있다. a는 우리가 찾아야할 패턴의 첫글자이기 때문이다. 따라서 a에는 1을 적어야 한다. 나머지 b,d 에는 0을 적는다. 이런식으로 테이블을 채워 나가면 다음과 같은 테이블이 나올 것이다.
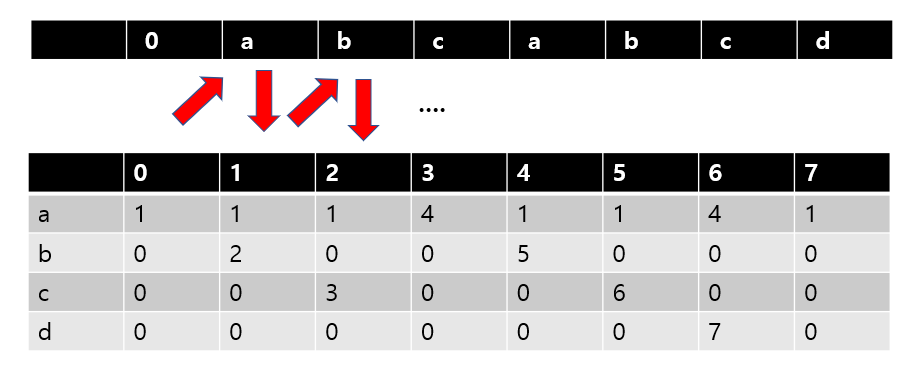
이런식으로 테이블을 보고 패턴을 찾아나가는 방법이다.
코드로 짜면 대강 이런 형식으로 나오게 된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
int table[4][8] = {(1,1,1,4,1,1,4,1),
{.......;
int DFmatch (char T[], int n, int output[])
{
int i;
i = 0; s = 0;
output[i] = s; // i번째 글자에 s를 쓰고 시작
for (i =1; i<=n; i++){
output[i] = Table[T[i]-'a'][s]; // text 글자를 a=0 b=1 c=2 d=3 으로 바꿈
s = output[i];
}
}
|
이 알고리즘의 공간과 시간은 얼마나 될까? 보통 우리가 쓰는 알파벳을 시그마(∑ = alphabet)로 표시를 한다.
공간은 테이블의 크기와 같으므로 O(|∑|m) (알파벳사용 갯수 * 패턴 크기) 이라고 생각하면 된다.
시간은 O(|∑|m+n) 이다.
테이블을 만드는 것은 다행히 만들어주는 알고리즘이 있고, 루프를 n까지 돌기 때문에 다음과 같이 나오게 된다.

다음포스트에서는 위의 2개의 알고리즘보다 더 빠른 KMP 알고리즘에 대해 알아보는 시간을 가지겠다. 좀 더 복잡한 내용이 될거 같아서 오늘 포스팅은 여기서 마무리하겠다.
'프로그래머, 보안 관련 지식 > 자료구조' 카테고리의 다른 글
| 자료구조 : Stack & Queue(1) (0) | 2020.04.17 |
|---|---|
| 자료구조: String Matching(2) (0) | 2020.04.17 |
| 자료구조 : Array for Search, Insert, Delete (0) | 2020.04.16 |
| 자료 구조 : Selection Sort, Merge Sort(2) (0) | 2020.04.15 |
| 자료 구조 : Selection Sort , Merge Sort (1) (0) | 2020.04.15 |



